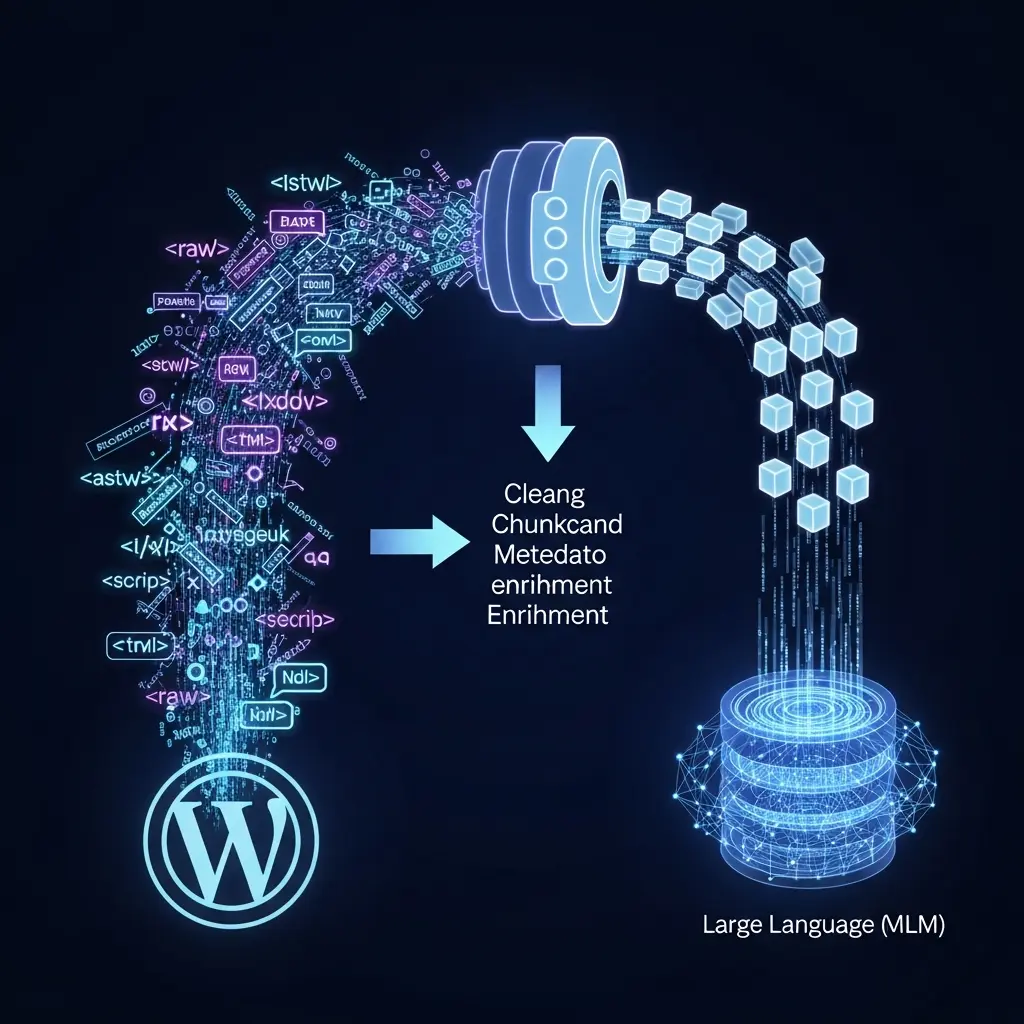
Cześć! Zapewne znasz ten ból: masz świetny pomysł na aplikację opartą o duży model językowy (LLM), która ma czerpać wiedzę z Twojej strony na WordPressie. Chcesz stworzyć inteligentnego chatbota, zaawansowaną wyszukiwarkę semantyczną albo system odpowiadania na pytania (Q&A). Konfigurujesz architekturę RAG (Retrieval-Augmented Generation), podpinasz model i… wyniki są, delikatnie mówiąc, rozczarowujące. Model halucynuje, odpowiedzi są nieprecyzyjne, a całość działa po prostu źle.
Problem rzadko leży w samym modelu. Najczęściej leży w danych, którymi go karmisz. Surowa treść z WordPressa, pełna tagów HTML, shortcode’ów i osadzonych skryptów, to dla LLM-a cyfrowy odpowiednik śmieciowego jedzenia. W tym wpisie pokażę Ci, jak przejść od chaosu w bazie danych WordPressa do uporządkowanego i gotowego do użycia indeksu wektorowego. Zrobimy to krok po kroku, w sposób ekspercki, ale na luzie.
Spis treści
- Fundamenty: Przygotowanie danych z WordPressa
- Dynamiczny indeks wektorowy: Jak utrzymać go w formie?

Fundamenty: Przygotowanie danych z WordPressa
Zanim jakikolwiek fragment tekstu trafi do modelu embeddingującego i bazy wektorowej, musi przejść przez solidny proces przygotowawczy. To jest ta „brudna robota”, która decyduje o sukcesie całego projektu. Zaniedbanie tego etapu to prosta droga do frustracji.
Krok 1: Ekstrakcja i czyszczenie – z HTML do czystego tekstu
Treść posta w WordPressie jest przechowywana w bazie danych jako blok HTML-a. Znajdziesz tam wszystko: od paragrafów <p>, przez nagłówki <h2>, po tagi formatujące jak <strong> czy <em>, a czasem nawet inline’owe style CSS. Dla Twojej aplikacji RAG to po prostu szum. Pierwszym zadaniem jest pozbycie się go.
Możesz to zrobić za pomocą bibliotek do parsowania HTML, takich jak BeautifulSoup w Pythonie. Proces wygląda następująco:
- Pobierasz treść posta (np. przez WordPress REST API).
- Używasz parsera, aby wyciągnąć sam tekst z tagów HTML.
- Usuwasz pozostałości, takie jak shortcode’y (np.
[galeria id="123"]), nadmiarowe białe znaki i puste linie.
Pamiętaj o złotej zasadzie przetwarzania danych: „Garbage in, garbage out”. Jeśli wpuścisz do systemu cyfrowe śmieci w postaci tagów HTML, otrzymasz bezwartościowe wektory i nieprecyzyjne odpowiedzi.
Krok 2: Chunkowanie, czyli dziel i zwyciężaj
Gdy masz już czysty tekst, nie możesz go wrzucić w całości do modelu. Po pierwsze, modele embeddingujące mają limity na długość tekstu. Po drugie, długie dokumenty prowadzą do „rozmytych” wektorów, które słabo sprawdzają się w wyszukiwaniu semantycznym. Rozwiązaniem jest chunkowanie, czyli inteligentne dzielenie tekstu na mniejsze fragmenty (chunki).
Jak to zrobić dobrze?
- Chunkowanie po zdaniach lub akapitach: To najlepszy start. Dzielenie tekstu w naturalnych granicach (kropka, nowy akapit) pozwala zachować spójność semantyczną.
- Recursive Character Text Splitter: Popularna technika (np. w LangChain), która próbuje dzielić tekst rekurencyjnie, zaczynając od największych separatorów (np. podwójny enter), a kończąc na pojedynczych znakach, jeśli to konieczne.
- Overlap (zakładka): Kluczowa technika. Każdy kolejny chunk powinien zawierać mały fragment końcówki poprzedniego. Dzięki temu, jeśli istotna informacja znajduje się na granicy dwóch chunków, nie tracimy kontekstu.
Krok 3: Wzbogacanie o metadane – kontekst jest królem
Sam tekst to nie wszystko. Każdy chunk powinien być wzbogacony o metadane. To one pozwolą Ci później filtrować wyniki, odsyłać użytkownika do źródła i debugować system. To absolutny „game changer” w każdej poważnej aplikacji RAG.
Co warto dodać do metadanych każdego chunka pochodzącego z WordPressa?
post_id: Unikalny identyfikator posta.source_url: Bezpośredni link do oryginalnego artykułu.title: Tytuł posta.published_date/modified_date: Daty publikacji i ostatniej modyfikacji.categories/tags: Kategorie i tagi przypisane do posta.chunk_index: Numer porządkowy chunka w ramach danego dokumentu.
Dzięki temu możesz później zadać pytanie w stylu: „Znajdź informacje o X, ale tylko w artykułach opublikowanych po 2023 roku w kategorii 'Sztuczna Inteligencja’”. Bez metadanych byłoby to niemożliwe.
Dynamiczny indeks wektorowy: Jak utrzymać go w formie?
Stworzenie indeksu po raz pierwszy to jedno. Prawdziwe wyzwanie zaczyna się, gdy treści na stronie żyją własnym życiem: autorzy dodają nowe posty, aktualizują stare, a czasem coś usuwają. Twój indeks wektorowy musi na to reagować, inaczej szybko stanie się nieaktualny.
Wersjonowanie treści – czyli skąd mam wiedzieć, co się zmieniło?
Codzienne przetwarzanie całej bazy danych WordPressa od nowa jest nieefektywne i kosztowne. Musisz wiedzieć, które treści uległy zmianie. Najprostsze podejście to poleganie na dacie modyfikacji (post_modified). Lepszym i bardziej niezawodnym sposobem jest hashowanie treści.
Stwórz hash (np. SHA256) z oczyszczonej treści każdego posta i przechowuj go razem z metadanymi w swojej bazie kontrolnej. Podczas kolejnej synchronizacji, oblicz hash dla aktualnej treści. Jeśli hashe się różnią – treść została zmieniona i wymaga ponownego przetworzenia.
Strategie aktualizacji indeksu – co zrobić, gdy autor kliknie „Aktualizuj”?
Gdy już wiesz, że post się zmienił, musisz odpowiednio zareagować. Oto trzy podstawowe scenariusze:
- Nowy post: Standardowa ścieżka. Czyścisz, chunkujesz, tworzysz embeddingi i dodajesz nowe wektory wraz z metadanymi do indeksu.
- Zaktualizowany post: To najważniejszy przypadek. Musisz najpierw usunąć wszystkie stare wektory powiązane z tym postem (dlatego
post_idw metadanych jest tak ważny!), a dopiero potem dodać nowe, wygenerowane na podstawie zaktualizowanej treści. W przeciwnym razie w Twoim indeksie będą żyły „duchy” starych informacji. - Usunięty post: Podobnie jak wyżej, musisz zidentyfikować wszystkie wektory powiązane z usuniętym
post_idi bezwzględnie usunąć je z bazy wektorowej.
Najlepiej zautomatyzować ten proces, używając webhooków w WordPressie (np. za pomocą akcji save_post i delete_post), które będą informować Twoją aplikację o każdej zmianie w czasie rzeczywistym.
Mam nadzieję, że ten przewodnik rozjaśnił nieco proces przygotowywania danych z WordPressa dla systemów RAG. To kluczowy, choć często pomijany element, który decyduje o jakości i niezawodności Twojej aplikacji AI. Jeśli chcesz podyskutować o tym lub innych tematach związanych z AI i developmentem, zapraszam do przejrzenia mojego portfolio na https://michalzareba.pl/.
Dodaj komentarz